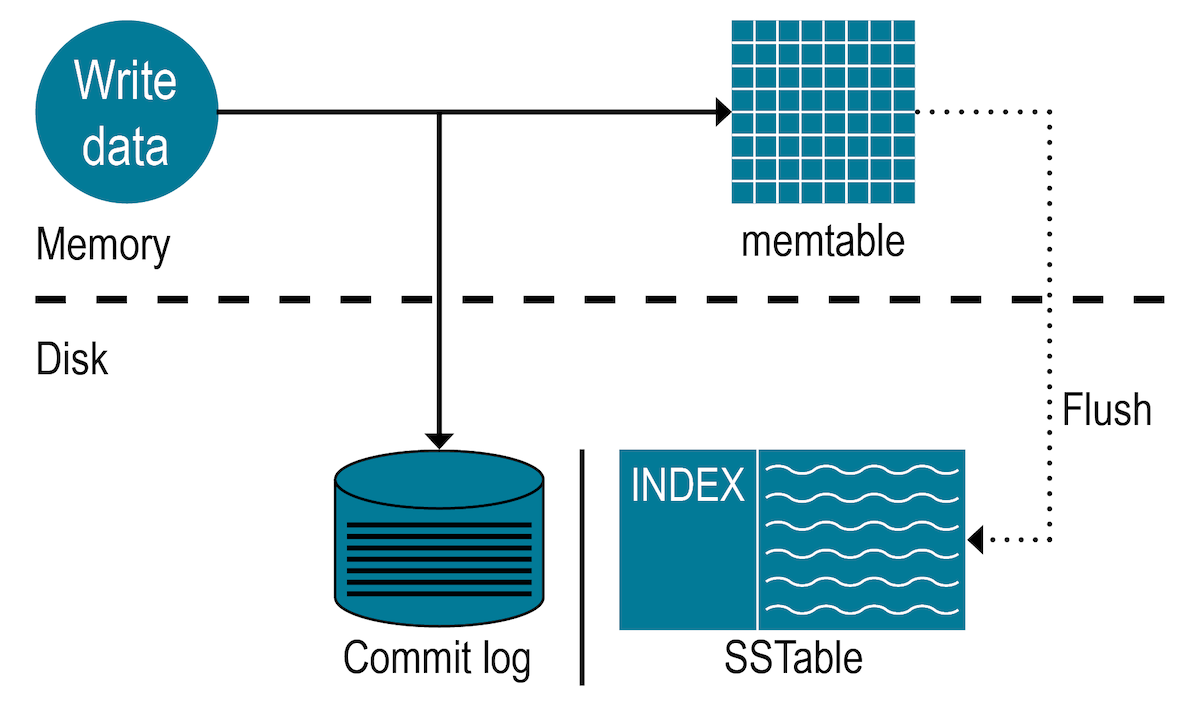

Memtable
A data structure that holds data in memory before it’s flushed to disk.
For a write operation, we write to memory, which is fast compared to persistent storage. Eventually, a memtable will surpass a predefined memory threshold and will need to be flushed to disk. While we can define our own write format, we can write the memtable in a sorted way to disk as an SSTable (see SSTable below). Once data is written to disk, it becomes immutable (the SSTable cannot be modified). Therefore, new writes go to a new memtable, and operations like updates or deletes on existing data in the previous memtable are instead stored in the new memtable.
For a read operation, we first check the current memtable. If the read can’t be fulfilled by the current memtable (perhaps the data exists but is no longer in memory because it was flushed to disk), we then check recently created SSTables in decreasing order of creation until we find the desired record (or we might not find it at all). Because the SSTable is sorted, it enables faster reads, as we can use binary search to find it in the file.
A memtable can be implemented with a Red-Black Tree, a SkipList, a HashSkipList, or a HashLinkList. For tradeoffs on these implementations, please check the RocksDB wiki .
Applications
Example: Design a time-series database with the following requirements:
- For the current time, write a given value for a given list of labels. A label is a pair
labelKey=labelValue, e.g.,[method=http, type=POST, statusCode=200] 1(the value is1). - The labels can be arbitrary strings.
- Reads will be for an arbitrary combination of labels and will cover a range of time (common).
- Reads will be for an arbitrary combination of labels and will cover a point in time (rare).
- A write-heavy system.
- 99% of the data is never queried after 24 hours.
A memtable fits this problem because it’s a write-heavy system (therefore, we need fast writes). The common scenario of reads for a range of time would also fit a linked list (either a SkipList or a HashLinkList). After a memtable is written to disk as an SSTable, it enables slower reads for old data, which is an acceptable tradeoff because 99% of the data is never queried after 24 hours.
Let’s define an entry as a data structure that holds a collection of labels, a single value, and a time.
type Entry struct {
// id is the time an entry was created (not threadsafe)
id time.Time
// labels are the labels that identify the entry.
labels map[string]string
// value is the entry value.
value any
// next is a pointer to the next Entry.
next *Entry
}
// example:
entry := &Entry{
id: time.Now(),
labels: map[string]string{
"method": "http",
"type": "POST",
"statusCode": "200",
},
value: 1,
}
Our memtable is a collection of entries stored in a linked list. The memtable has pointers to the head and tail
of the linked list. index is explained later in this article.
type Memtable struct {
// head is the head of the linked list.
head *Entry
// tail is the head of the linked list.
tail *Entry
// index is a reverse index of a label to an entry.
index map[string][]*Entry
}
On a write, a new entry is added to the tail of the memtable’s linked list.
func (m *Memtable) Write(labels map[string]string, value any) {
e := &Entry{
id: time.Now(),
labels: labels,
value: value,
}
// process entry
for k, v := range labels {
key := m.encode(k, v) // encode creates a unique key in the HashMap
m.index[key] = append(m.index[key], e)
}
m.tail.next = e
m.tail = m.tail.next
}
To find entries by label(s), we can iterate through the linked list from head to tail, collecting
entries that match our labels in O(n), where n is the size of the linked list. To improve query performance,
we can use an index that maps a label to the locations of entries. This speeds up the find operation
to O(k), where k is the maximum number of entries mapped to a label. The tradeoff is space
and the fact that we have to update the index on every write.
With the above, we get values for single labels. For multiple labels, we combine the results by performing an intersection.
func (m *Memtable) Read(labels map[string]string) []any {
// read temporary results for every label
entriesGroup := make([][]*Entry, 0)
for k, v := range labels {
key := m.encode(k, v)
entriesGroup = append(entriesGroup, m.index[key])
}
// intersect
if len(entriesGroup) == 0 {
return make([]any, 0)
}
intersectedEntries := entriesGroup[0]
for i := 1; i < len(entriesGroup); i += 1 {
intersectedEntries = intersect(intersectedEntries, entriesGroup[i])
}
out := make([]any, 0)
for _, entry := range intersectedEntries {
out = append(out, entry.value)
}
return out
}
SSTable
An immutable data structure that stores a large number of key:value pairs sorted by key.
Advantages over simple hash indexes
- Merging SSTables is similar to doing a merge sort.
- To find if a key exists, we don’t need an index of all the keys in memory. Instead, we can keep a sparse index for every few kilobytes and then perform a scan.
- Range queries can be compressed before writing to disk; the sparse index would only need to find the starting position of the compressed segment.
