Engine
Features
- Consistent hashing
- Replication factor: replicas of the data across the cluster.
- Consistency level controlled for each query
- Up to 2 billion key-value pairs in a row.
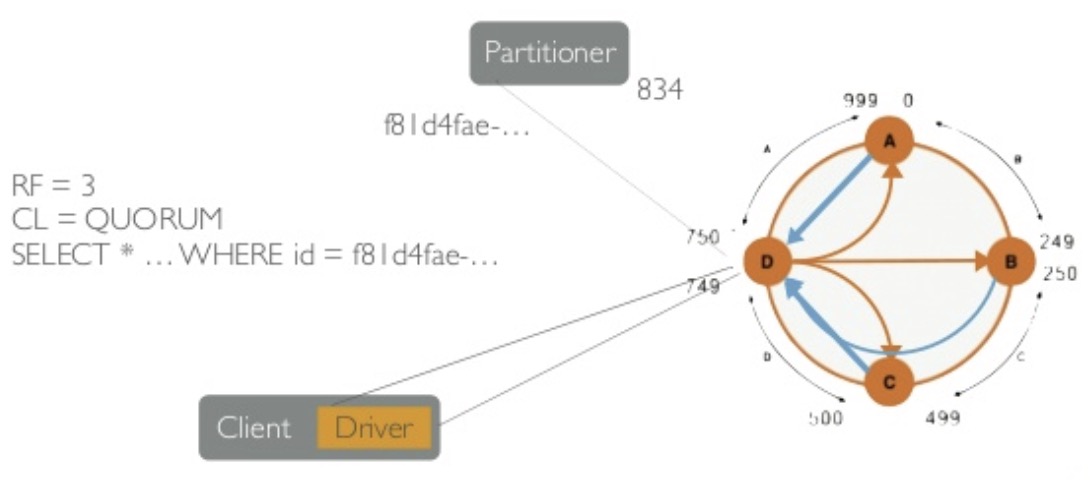
Cassandra replication
- Replication factor = 3
- Consistency level = QUORUM
- Clients talk to any node. The node hashes the partition key and finds the location of the data.
- Data is read from all the replicas, waiting for responses until we reach a quorum.
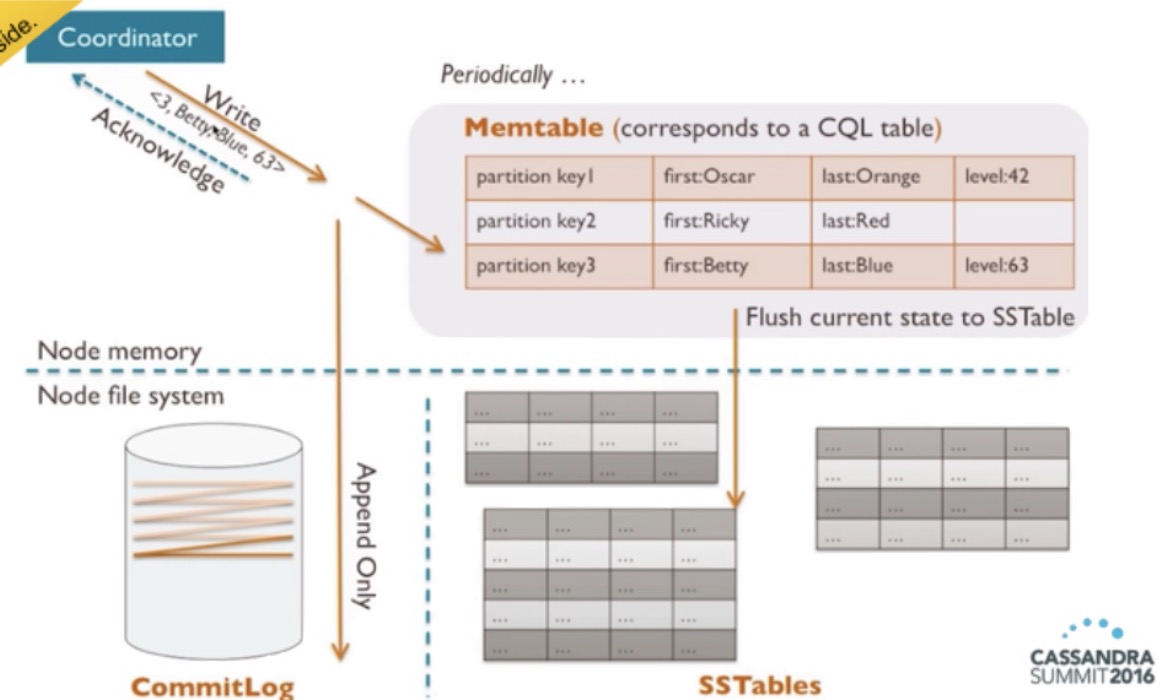
Cassandra write
- Acknowledged when we write to both the commit log (append-only) and the memtable.
- When the memtable becomes full, it’s flushed into an SSTable.
- Periodically, SSTables are merged.
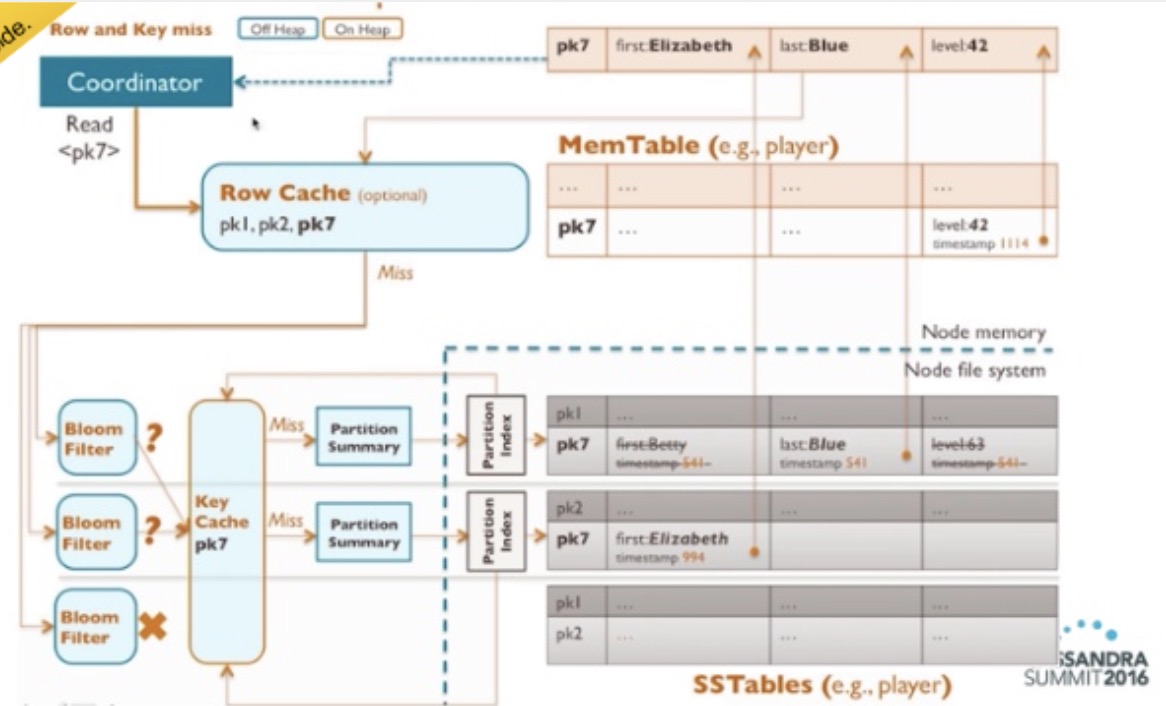
Cassandra read
- Check if the key is in the in-memory row cache.
- Query the Bloom filters of the existing SSTables to find the record. If it doesn’t exist, then skip the SSTable.
- If the Bloom filter says that there may be data, check the in-memory key cache.
- On a miss, get the data from the SSTable and merge it with the data in the memtable. Write the key to the in-memory key cache and the merged result to the in-memory row cache.
Data modeling
Goals
- Spread data evenly around the cluster.
- Minimize the number of partitions read.
- Keep partitions manageable.
Process
- Identify initial entities and relationships.
- Key attributes (map to PK columns).
- Equality search attributes (map to the beginning of the PK).
- Inequality search attributes (map to clustering columns).
- Other attributes:
- Static attributes are shared within a given partition.
primary key = partition key + clustering columns
Legend:
K Partition key
C Clustering key and their ordering (ascending or descending)
S Static columns, fixed and shared per partition
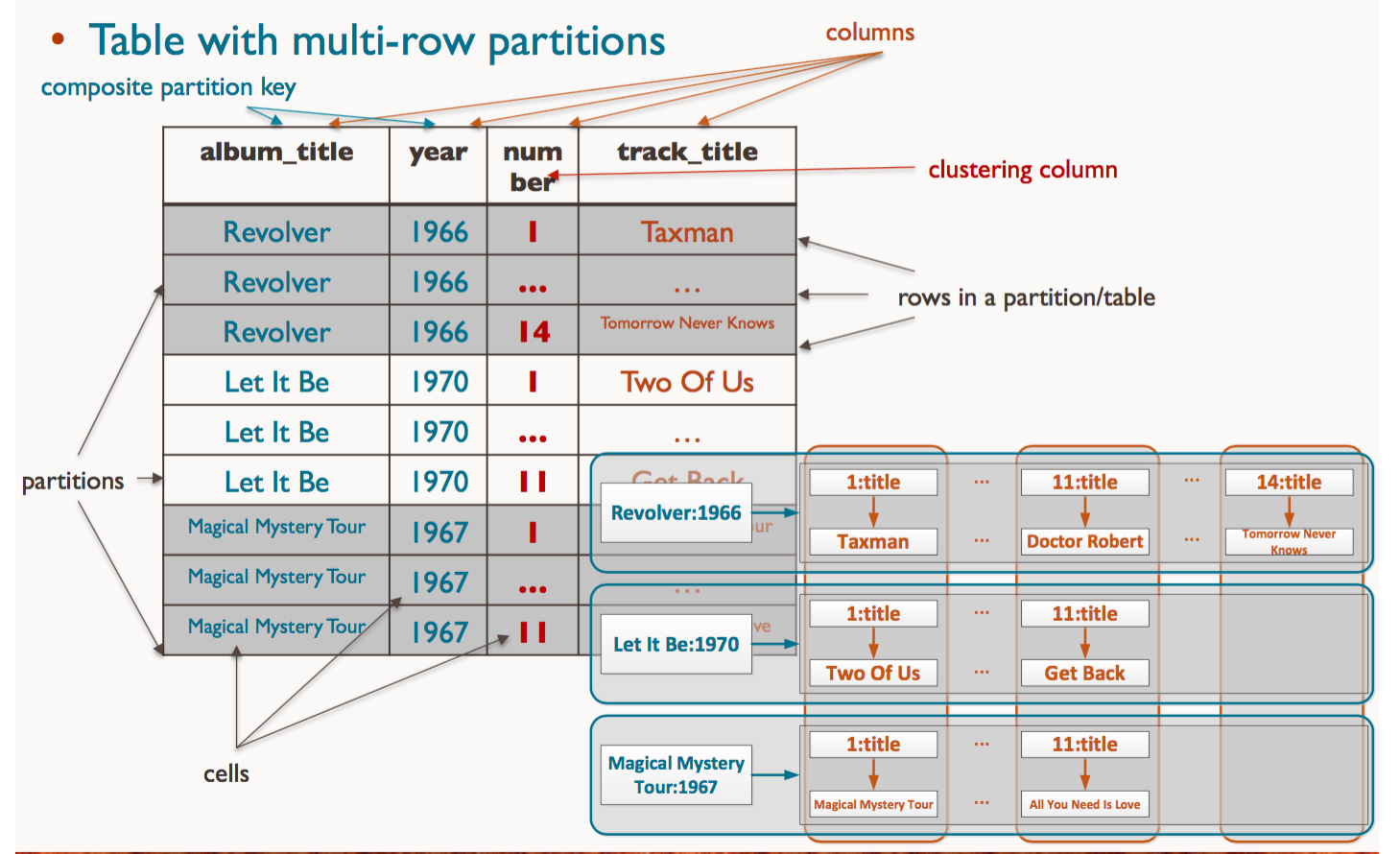
Cassandra table structure
Validation
- Is data evenly spread?
- One partition per read?
- Are writes (overwrites) possible?
- How large are the partitions? Let’s assume that each partition should have at most 1M cells:
- How much data duplication?
Examples
Store books by ISBN
| Attribute | Special |
|---|---|
| isbn | K |
| title | |
| author | |
| genre | |
| publisher |
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions?
- How much data duplication? 0
Register a user uniquely identified by an email/password. We also want their full name. They will be accessed by email and password or by UUID.
| Attribute | Special |
|---|---|
| K | |
| password | C |
| fullname | |
| uuid |
Q1: Find users by login info.
Q3: Find users by email (to guarantee uniqueness).
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions?
- How much data duplication? 0
| Attribute | Special |
|---|---|
| uuid | K |
| fullname |
Q2: Get users by UUID.
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions?
- How much data duplication? 0
Find books a logged-in user has read, sorted by title and author.
| Attribute | Special |
|---|---|
| uuid | K |
| title | C |
| author | C |
| fullname | S |
| ISBN | |
| genre | |
| publisher |
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions? (up to 200k book reads per user)
- How much data duplication? 0
Interaction of every user on the website
| Attribute | Special |
|---|---|
| uuid | K |
| time | C (desc) |
| element | |
| type |
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions? (up to 333k book reads per user; 333k actions may be a low number of actions to store, therefore we should store actions by bucket)
- How much data duplication? 0
| Attribute | Special |
|---|---|
| uuid | K |
| month | K |
| time | C (desc) |
| element | |
| type |
- Is data evenly spread? Yes
- 1 partition per read? Yes
- Are writes (overwrites) possible? Yes
- How large are the partitions? (up to 333k book reads per user)
1 year = 333k / 365 / 24 = 38 actions / h
1 month = 333k / 30 / 24 = 462 actions / h (most realistic case)
1 week = 333k / 7 / 24 = 1984 actions / h
- How much data duplication? 0