Count min sketch
Problem: given a stream of data with keys and values, how can we get the sum of all values for a given key?
Approximate solution: Assume that we have $d$ counter hash maps, each with its own hash function. Every time we
see a new key/value, we add it to all the $d$ counter hash maps (update). To get the sum of values (estimate), we
take the hash of the key and return the minimum value of the counters in all $d$ hash maps.
Because the counter hash map size is finite, we will have collisions, and a hash map may report a higher sum than the
true value.
Images taken from: Algorithms and Data Structures for Massive Datasets
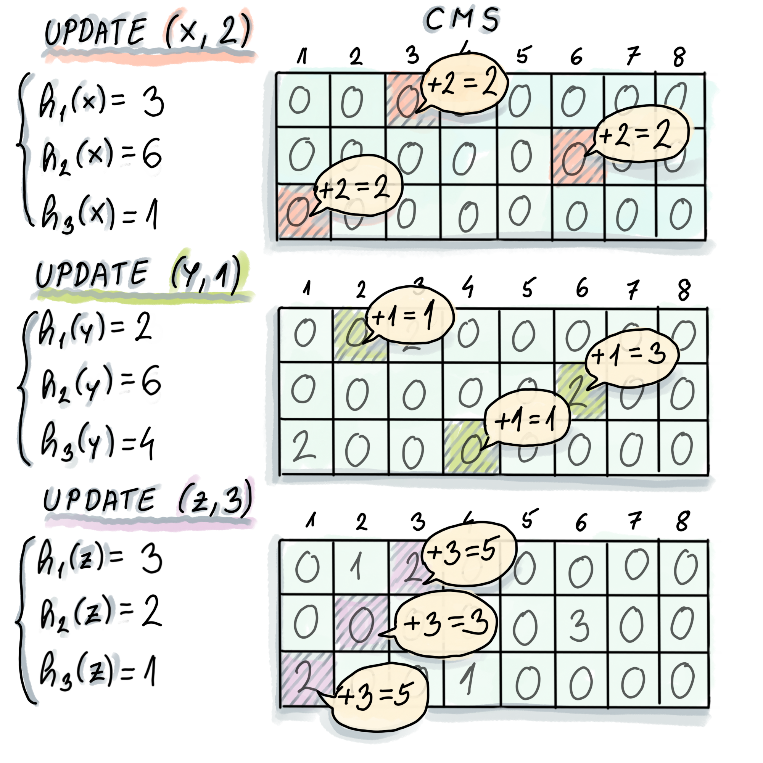
Update
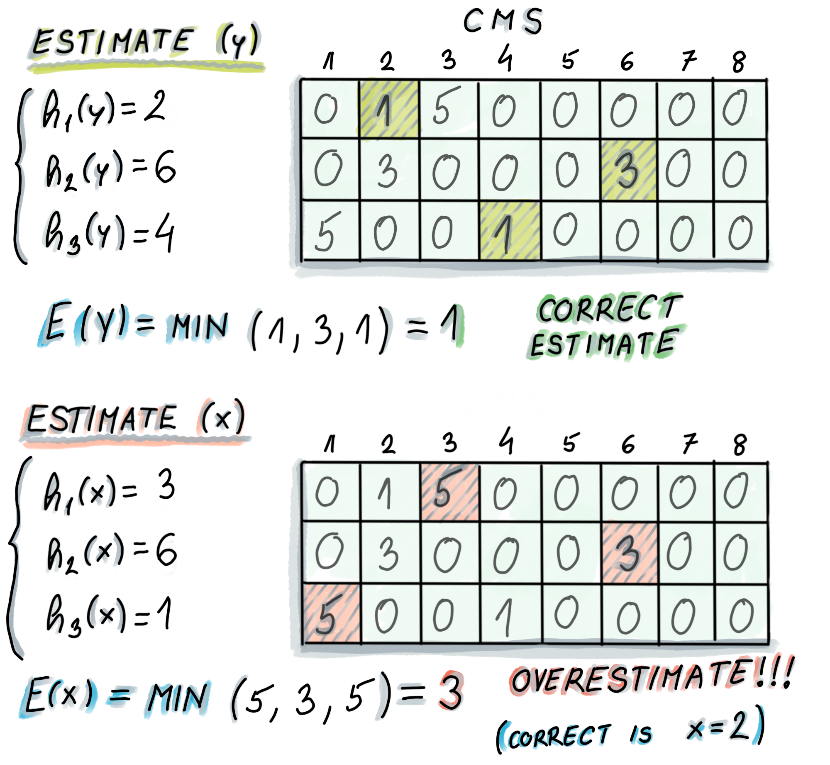
Estimate
https://florian.github.io/count-min-sketch/
Applications
Top k elements: Every time we update the count-min sketch, we also call estimate and insert the record
into a min-heap. When the heap’s capacity is greater than $k$, we remove the top item from the heap.
Similarity of words: Assume that we have a stream of pairs (word, context). The problem is to find if two words,
A and B, are similar in meaning based on the context in which they appear. The similarity of two words is computed with:
To solve the problem, we can create a matrix of size O(number of words * number of contexts).
The intuition behind this formula is that it measures how likely A and B are to occur close to each other (numerator)
in comparison to how often they would co-occur if they were independent (denominator).
To answer queries, we can use a matrix $M$ where the entry $M_{A,B}$ contains the number of times the word A appears in the context B. The problem is that the number of word-context pairs quickly gets out of hand.
The solution is to transform the matrix such that the word-context pair frequencies are stored in the count-min sketch; the occurrences of words and contexts are kept in other hash maps.
Range queries: Use a segment tree where each node is a CMS.
Images taken from: Algorithms and Data Structures for Massive Datasets
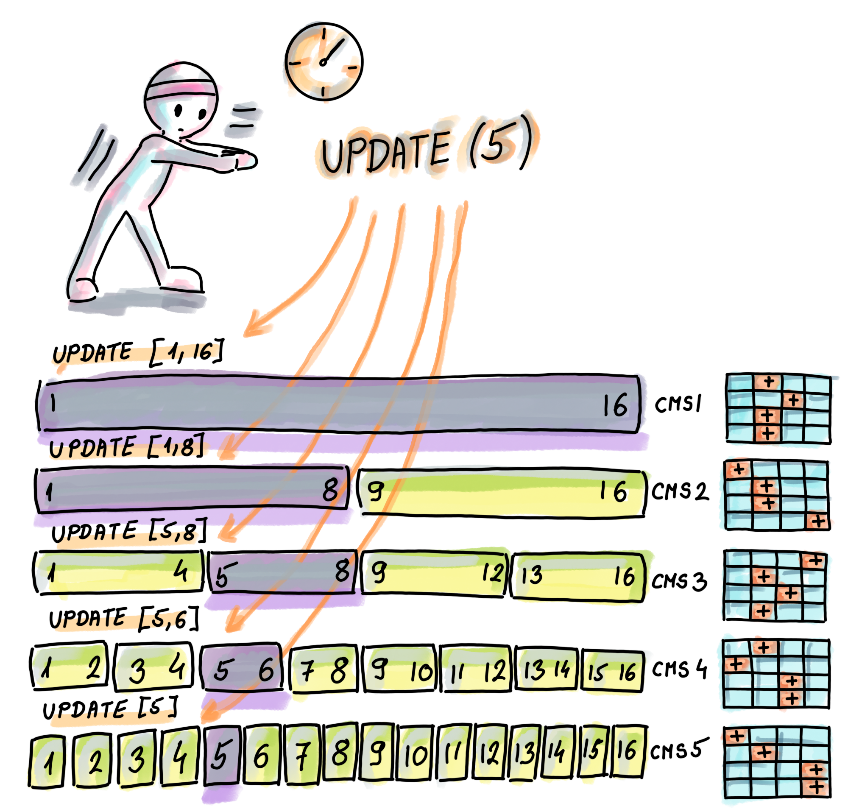
Update
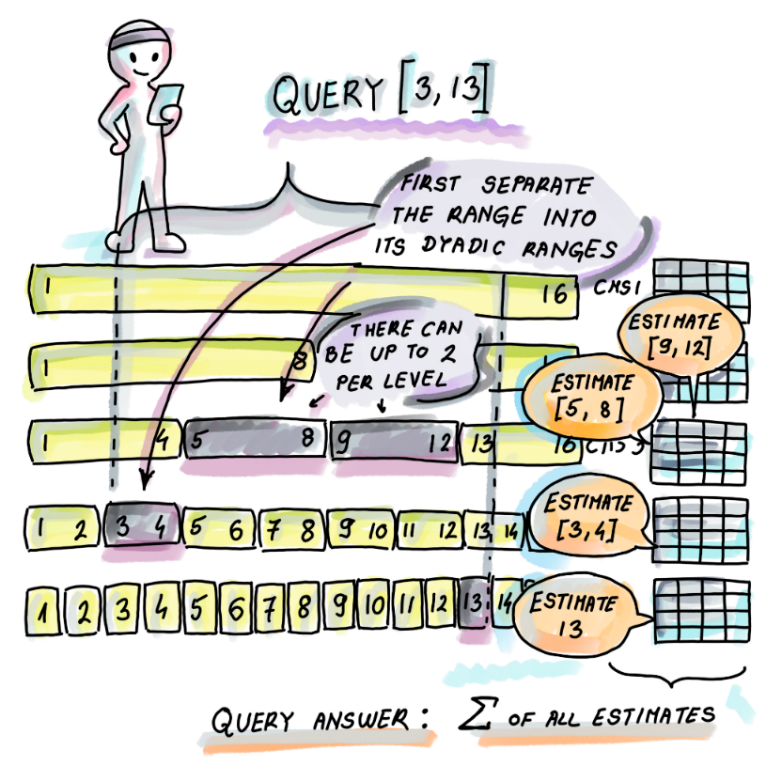
Read
e-approximate heavy hitters: In a stream where the total number of frequencies is $n$ (for example, if all frequencies are 1, then $N$ corresponds to the number of elements encountered so far in the stream), output all the items that occur at least $n/k$ times. When $k=2$, this problem is known as the majority element.
If $n$ is known in advance, we can process the array elements using a count-min sketch in a single pass and remember an element once its estimated frequency (according to the count-min sketch) is at least $n/k$.
If $n$ is not known in advance, we use a min-heap. In a single pass, we maintain the number of elements seen so far, $m$.
When processing the next element, $x$, we call update(x, 1) and then estimate(x).
If the estimate is $\geq m/k$, we store $x$ in the heap. Also, whenever $m$ grows to the point that some object $x$ stored
in the heap has a key less than $m/k$ (checkable in O(1) time via Find-Min),
we delete $x$ from the heap (via Extract-Min). After finishing the pass, we output all the objects in the heap.
Trending hashtags: Quantify how different the currently observed activity is against an estimate of the expected activity. For each hashtag, store how many times it’s shared in an X-minute window over the last Y days, $C(h, t)$ (normalized to get $P(h, t)$, i.e., $P(h, t) = \tfrac{C(h, t)}{\sum_{i=0}^{n}C(h, t_i)}$). At a new time $t$, we can compute $C(h, t)$ and $P’(h, t)$, then use KL divergence to measure the difference between the probabilities.
The top $k$ trending hashtags can be computed with a heap.
Based on https://instagram-engineering.com/trending-on-instagram-b749450e6d93
Bloom filter
Problem: Test if an element doesn’t exist in a set.
Approximate solution: Similar to a count-min sketch, if the returned value is zero, then we’re sure the element is not in the set. Otherwise, it might be in the set, and we need to test for existence with another (more expensive) data structure.
For more info read:
Applications
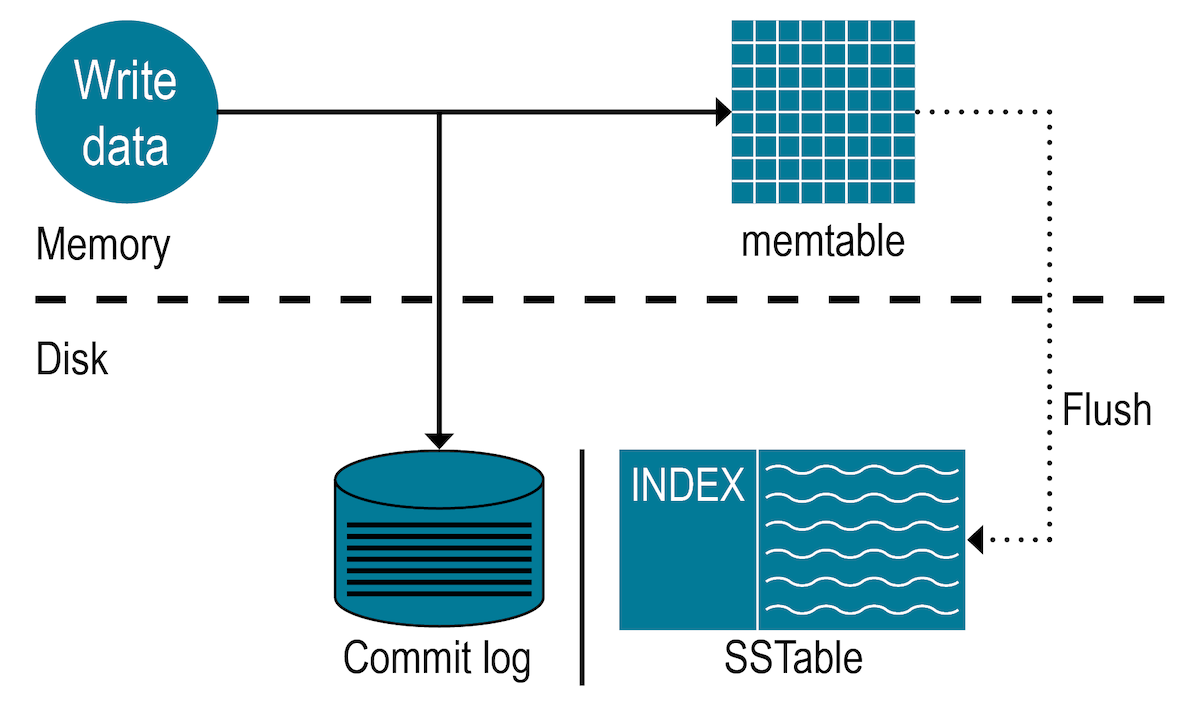
SSTable reads: In the read path, Cassandra merges data on disk (in SSTables) with data in RAM (in memtables). To avoid checking every SSTable data file for the requested partition, we can query the SSTable’s bloom filter.
Reservoir sampling
Problem: Given a stream of elements, we want to sample k random ones without replacement and with uniform probability.
Solution: Store the first $k$ elements. For the $i$-th element (where $i > k$), add it to the reservoir with a probability of $k/i$. This is done by replacing a randomly selected element in the reservoir.